Post-processing
To ensure high-quality and synchronized data, several post-processing steps were applied after recording:
1. High-Pass Filtering
A 5th-order Butterworth high-pass filter with a 50 Hz cutoff was applied to the throat microphone (accelerometer) data to remove low-frequency noise, including gravitational acceleration components.
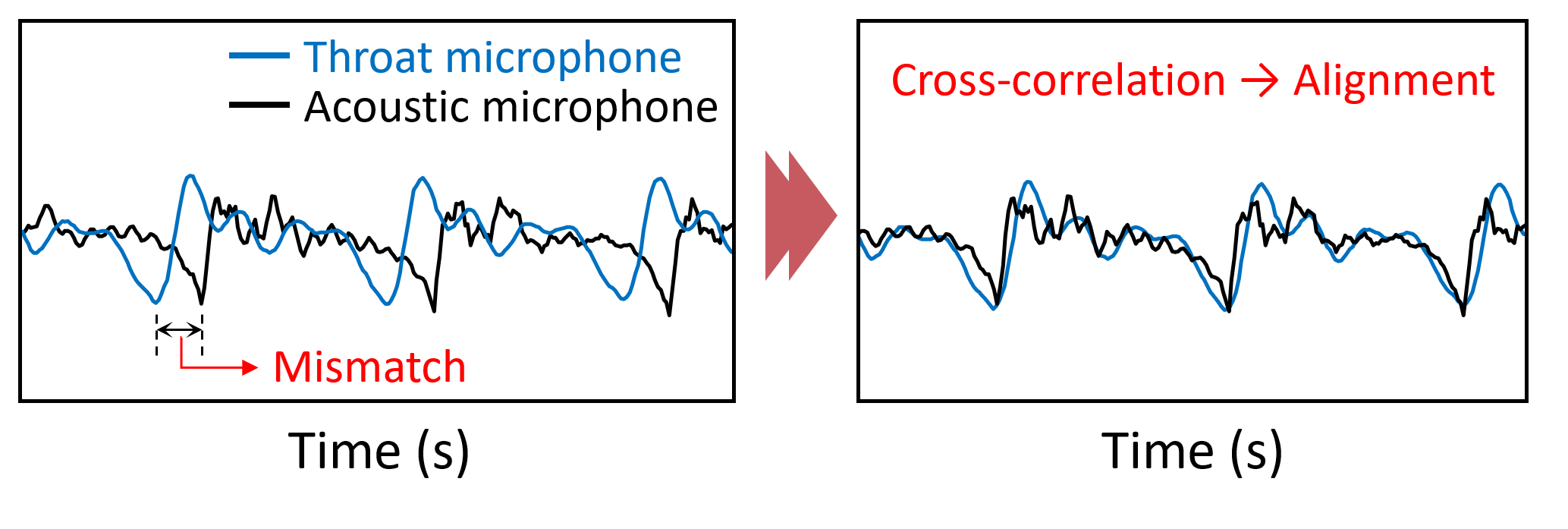
2. Timing Alignment
To correct mismatches caused by timing differences between throat and acoustic microphone signals, synchronization adjustments were applied. This alignment step is crucial for training robust deep learning models.
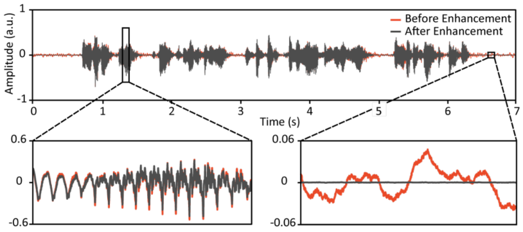
3. Noise Reduction
Minor background noise in acoustic microphone recordings was removed using the pretrained causal version of the Demucs speech enhancement model.
4. Silence Trimming & Manual Review
Silent segments at the beginning and end of each utterance were manually trimmed. Every recording was reviewed to ensure accurate pronunciation and sentence alignment.
5. Upsampling
The throat microphone recordings were upsampled from 8 to 16 kHz to match the sampling rate of the acoustic recordings.